예전에 RFM 등급을 통해 고객 데이터를 분석해봤었는데 새로운 고객 분석 기법을 알기도 했고 제가 고객 분석하는 것을 제일 좋아하기에 재미있게 진행했던 기억이 있었습니다.
그래서 다른 데이터에도 RFM 분석을 적용해보고 싶어 이번 프로젝트를 준비해보았습니다.
https://www.kaggle.com/olistbr/brazilian-ecommerce
Brazilian E-Commerce Public Dataset by Olist
100,000 Orders with product, customer and reviews info
www.kaggle.com
캐글의 Brazilian E-coomerce Public 데이터를 이용해 고객 데이터 분석을 해보았습니다.

8개의 데이터가 있고 각 데이터들은 고유키를 기준으로 합칠 수 있습니다.
저는 이 중에서 olist_orders_dataset , olist_order_items_dataset , olist_customers_dataset 세 가지 데이터만을 사용할 것이기에 3가지의 데이터만 자세히 살펴보도록 하겠습니다.
✅ EDA
import pandas as pd
import urllib
import json
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import datetime
import numpy as np
from statsmodels.tsa.seasonal import seasonal_decompose
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans1. Orders

총 8개의 칼럼이 존재하며, 각 칼럼은 아래의 의미를 지닙니다.
- order_id: order unique 값
- customer_id : 고유한 customer_id (key)
- order_status : 주문의 상태
- order_purchase_timestamp : 구매 시간
- order_approved_at : 지불 승인된 시간
- order_delivered_carrier_date : 물류 파트너에게 처리된 경우, 주문 게시 시간을 표시함(물류팀에게 전달된 시간)
- order_delivered_customer_date : 실제 주문 배송이 시작된 시간
- order_estimated_delivery_date : 구매 시점에 고객에게 통지한 '예상 배송 날짜'
order.info()
2. Customer

5개의 컬럼을 보유하고 있습니다.
- customer_id : 고유한 customer_id (key)
- customer_unique_id : unique identifier (여러 번 가능)
- customer_zip_code_prefix : 우편번호
- customer_city : 고객이 거주하는 지역
- costomer_state : 고객이 거주하는 state
customer_id와 customer_unique_id의 의미가 헷갈려 자세히 살펴보니
customer.groupby('customer_unique_id').size().sort_values(ascending=False)
customer.groupby('customer_id').size().sort_values(ascending=False)

customer_unique_id는 중복된 경우가 몇 번 있었지만 customer_id는 모두 1번씩 나온 것을 볼 수 있었습니다.
아마 customer_id는 주문마다의 고객 고유 id일 것으로 생각됩니다. 또한 customer_unqiue_id는 고객 자체의 아이디 같습니다.
그렇기에 customer_id는 중복이 없으며 key가 될 수 있고, unique_id는 한 고객이 여러 번의 주문을 할 수 있기에 여러 번 중복된 것 같네요.
customer.describe(include='all')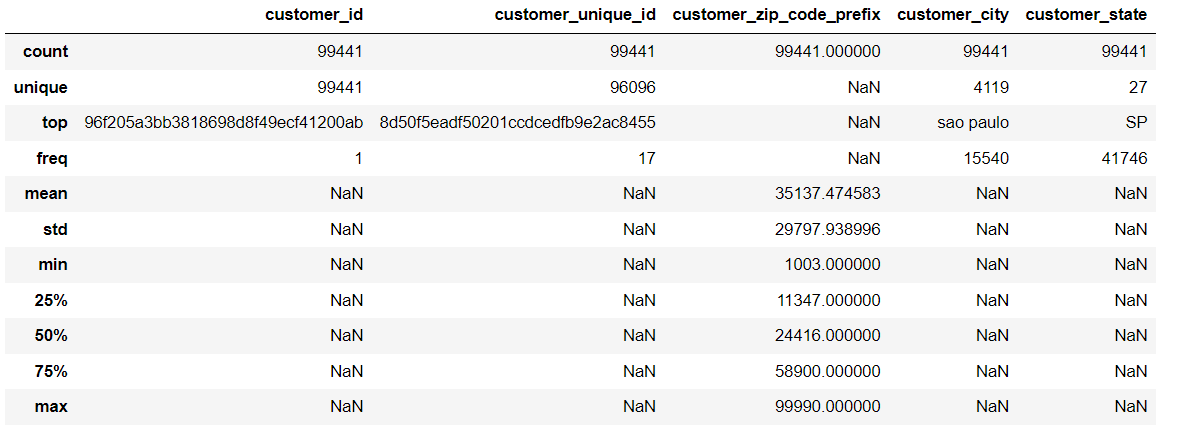
3. Item

- order_id : order의 unique 값
- order_item_id : 한 주문에서 아이템을 구분하기 위한 번호
💡order_id는 중복될 수 있다. 하나의 주문에서 여러 개의 물품을 주문할 수 있기 때문, 이를 구분하기 위해 item_id도 존재하는 듯하다.
- product_id : product unique 값
- seller_id : seller unique 값
- shipping_limit_date : 판매자 배송 날짜
- price : 물품 가격
- freight_value : 배송비 ( 한 주문에 여러개의 물품이 있는 경우 배송비는 1/n로 분할돼서 들어감)
item.describe(include='all')
CountStatus = pd.value_counts(item['order_item_id'].values, sort=True)
CountStatus.plot.bar()

대부분 한 주문당 1개의 제품인 것을 볼 수 있었습니다.
✅ RFM 계산
계산 식들은 아래의 링크를 참고했습니다 !
RFM Segmentation and Customer Analysis
Explore and run machine learning code with Kaggle Notebooks | Using data from Brazilian E-Commerce Public Dataset by Olist
www.kaggle.com
▪ 데이터 Merge
order_items_silver = item.groupby('order_id').agg({'price':sum,'freight_value':sum }).reset_index()우선 item 데이터를 order_id를 기준으로 그룹화해줍니다.
order_silver=order.merge(order_items_silver,on='order_id',how='inner')그룹화된 item데이터와 order 데이터를 merge 해줍니다.
orders_customers = customer.merge(order_silver, on='customer_id', how='inner')마지막으로 위의 데이터와 customer 데이터를 merge 해주면 됩니다.
그러면 14개의 열을 가진 데이터 프레임이 완성됩니다.
▪ RFM 변수 생성
Recency를 계산하기 위한 기준 날짜는 '전체 데이터들 중 제일 최근 날짜 +1일'로 지정하였습니다.
max_date = max(pd.to_datetime(orders_customers['order_purchase_timestamp'], errors='raise')) + datetime.timedelta(days=1)Timestamp('2018-09-04 09:06:57')저는 18년 9월 4일이 나왔네요.
rfm=orders_customers.groupby('customer_unique_id').agg(
{'order_purchase_timestamp':lambda x:(max_date-pd.to_datetime(x.max())).days,
'customer_id':'count',
'price':'sum'
}).reset_index()
rfm.columns=['customer_id','recency','frequency','monetary']merge 된 데이터를 customer_unique_id를 기준으로 그룹화해주었습니다.
또한 recency에는 최근 날짜 - 구매 마지막 날짜를 계산해주었고, frequency에는 구매 횟수를 , monetary에는 구매 물품 가격의 총합을 계산해주었습니다.
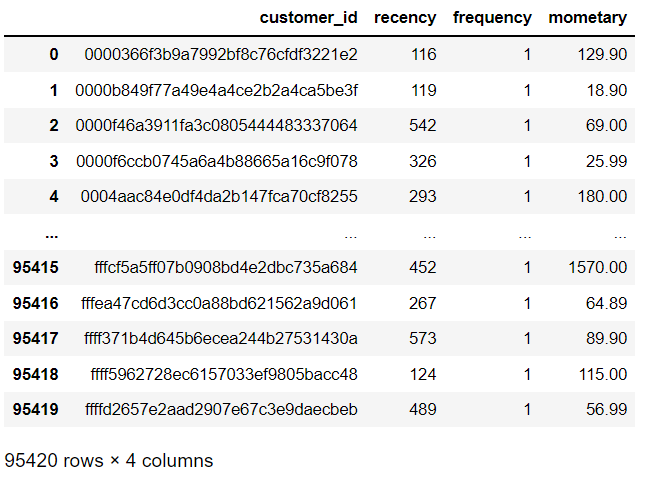
rfm['recency'].describe()
Recency의 통계량를 확인해보면 구매 마지막 날짜가 9월 4일로부터 평균 243일 정도 지난 것을 볼 수 있었습니다.
sns.histplot(rfm['recency'])
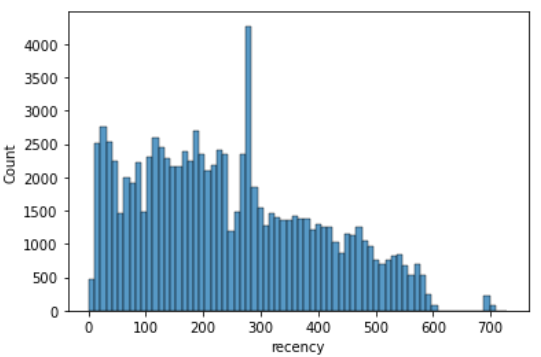
히스토그램으로 살펴보면 구매 마지막 날짜가 100~300일정도 지난 고객이 많은 편입니다.
rfm['frequency'].describe()

구매 빈도 frequency는 평균이 1.03이며,25%,50%,75% 값 모두 구매가 1회입니다.
대부분의 고객들이 1번의 구매경험이 있는 고객들임을 예상해볼 수 있었습니다.
rfm['monetary'].describe()
구매 금액 monetary는 평균 142달러입니다. (아마 달러겠죠..?)
하지만 50% 값인 89달러와 꽤 큰 차이가 납니다. max값이 너무 커서 평균이 영향을 받은 듯합니다.
▪ K-means로 그룹화
보통 RFM을 계산한 후, 각각의 등급을 만들어 주기 위해 분위수를 사용한다거나 최대값,최소값을 이용해 1~5등급으로 나누는 것 같습니다. 저도 이전에는 두 방법 중 하나를 사용했던 것 같아요.
이번에는 kmean로 등급을 나누어보려합니다. 그래서 그룹화를 위한 함수를 하나 만들어줍니다.
def k_means_group(data, n_clusters, random_state, asc=False, log_transf=False, standard_tranf=False):
data_temp = data.copy()
if log_transf:
data_temp = np.log(data_temp) + 1
if standard_tranf:
scaler = StandardScaler()
scaler = scaler.fit(data_temp)
data_temp = scaler.transform(data_temp)
kmeans_sel = KMeans(n_clusters=n_clusters, random_state=random_state).fit(data_temp)
cluster_group = data.assign(cluster = kmeans_sel.labels_)
mean_group = cluster_group.groupby('cluster').mean().reset_index()
mean_group = mean_group.sort_values(by=mean_group.columns[1],ascending=asc)
mean_group['cluster_set'] = [i for i in range(n_clusters, 0, -1) ]
cluster_map = mean_group.set_index('cluster').to_dict()['cluster_set']
return cluster_group['cluster'].map(cluster_map)(kmeans를 이용한 그룹화 코드는 캐글을 많이 참고했습니다.)
r_labels = k_means_group(rfm[['recency']],5,1,asc=True)
f_labels = k_means_group(rfm[['frequency']],5,1)
m_labels = k_means_group(rfm[['monetary']],5,1)
rfm = rfm.assign(R = r_labels, F = f_labels, M = m_labels)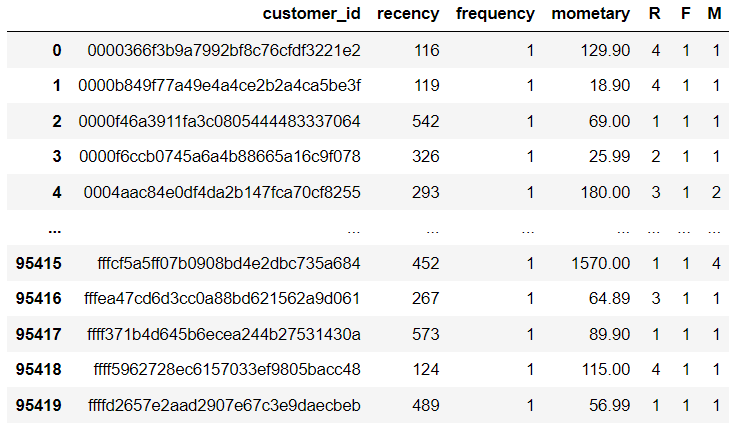
그룹화를 통해 RFM 각각의 계산을 완료하였습니다.
rfm.groupby('R')['recency'].describe()
1등급에서 5등급으로 갈수록 최근성, 빈도,금액이 높은 고객으로 보시면 됩니다.
예를 들어 R등급이 1인 경우 마지막 구매일이 447~729일인 고객들로 구성된 것입니다.
rfm.groupby('F')['frequency'].describe()
R등급에서 각 등급별로 고객의 수는 비교적 균등한 편이었는데 구매횟수는 1인 고객이 매우 많다보니 F등급별 고객의 수는 차이가 많이 나는 것을 볼 수 있습니다.
F등급이 1등급은 90000명인데 5등급인 고객은 1명입니다.
rfm.groupby('M')['monetary'].describe()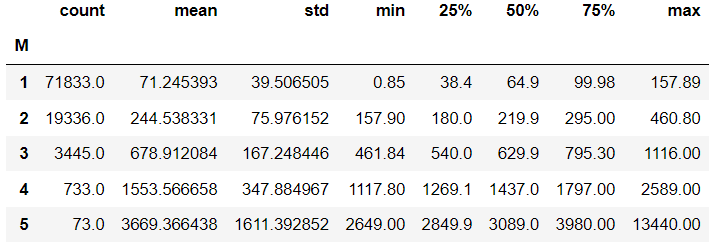
M등급 또한 등급별 고객의 수가 꽤 많이 차이가 나는 것을 볼 수 있습니다.
💡kmeans를 실행할 때 로그 변환을 넣어 정규화를 시켜줄 수도 있었지만, 제 생각으로는 RFM이 모두 균등하게 분배되는 것이 현실에서 불가능한 일인 것 같아 정규화를 시켜주지 않았습니다.
( 일반 고객보다 VIP가 훨씬 적은 것처럼)
이제 구한 RFM을 이용해 고객을 Segment 해볼 예정인데 그룹을 나누는 기준 또한 캐글을 참고하였습니다.
def get_segment(data):
mean_fm = (data['F'] + data['M']) / 2
if (data['R'] >= 4 and data['R'] <= 5) and (mean_fm >= 4 and mean_fm <= 5):
return 'Champions'
if (data['R'] >= 2 and data['R'] <= 5) and (mean_fm >= 3 and mean_fm <= 5):
return 'Loyal Customers'
if (data['R'] >= 3 and data['R'] <= 5) and (mean_fm >= 1 and mean_fm <= 3):
return 'Potential Loyslist'
if (data['R'] >= 4 and data['R'] <= 5) and (mean_fm >= 0 and mean_fm <= 1):
return 'New Customers'
if (data['R'] >= 3 and data['R'] <= 4) and (mean_fm >= 0 and mean_fm <= 1):
return 'Promising'
if (data['R'] >= 2 and data['R'] <= 3) and (mean_fm >= 2 and mean_fm <= 3):
return 'Customer Needing Attention'
if (data['R'] >= 2 and data['R'] <= 3) and (mean_fm >= 0 and mean_fm <= 2):
return 'About to Sleep'
if (data['R'] >= 0 and data['R'] <= 2) and (mean_fm >= 2 and mean_fm <= 5):
return 'At Risk'
if (data['R'] >= 0 and data['R'] <= 1) and (mean_fm >= 4 and mean_fm <= 5):
return "Can't Lose Then"
if (data['R'] >= 1 and data['R'] <= 2) and (mean_fm >= 1 and mean_fm <= 2):
return 'Hibernating'
return 'Lost'예를 들어 R이 1이고 (F+M)/2 가 1인 고객은 Hibernating으로 분류되는 것이죠.
F와 M을 더해 평균으로 계산하는 방법은 캐글에서 가져온 것인데 , R은 등급별로 골고루 분포되어있는데에 비해 F와 M은 등급별 고객의 수가 차이가 많이나서 이러한 과정을 사용한 것이 아닐까 예상해봅니다.
rfm 데이터프레임에 segment 결과를 넣어줍니다.
rfm['segment']=rfm.apply(get_segment,axis=1)
이렇게 되면 RFM 분류와 Segment는 모두 완료되었고 이를 파이썬에서 시각화해볼 수도 있지만 저는 csv로 저장해 태블로를 이용해 시각화하였습니다.
rfm.to_csv('olist_rfm.csv')
https://public.tableau.com/app/profile/fastcampustableau/viz/CH14-6Segmentation/RFM
CH14-6 Segmentation
CH14-6 Segmentation
public.tableau.com
그래프 제작 과정은 위의 대시보드를 참고하였습니다.
제가 최종적으로 만든 대시보드입니다.
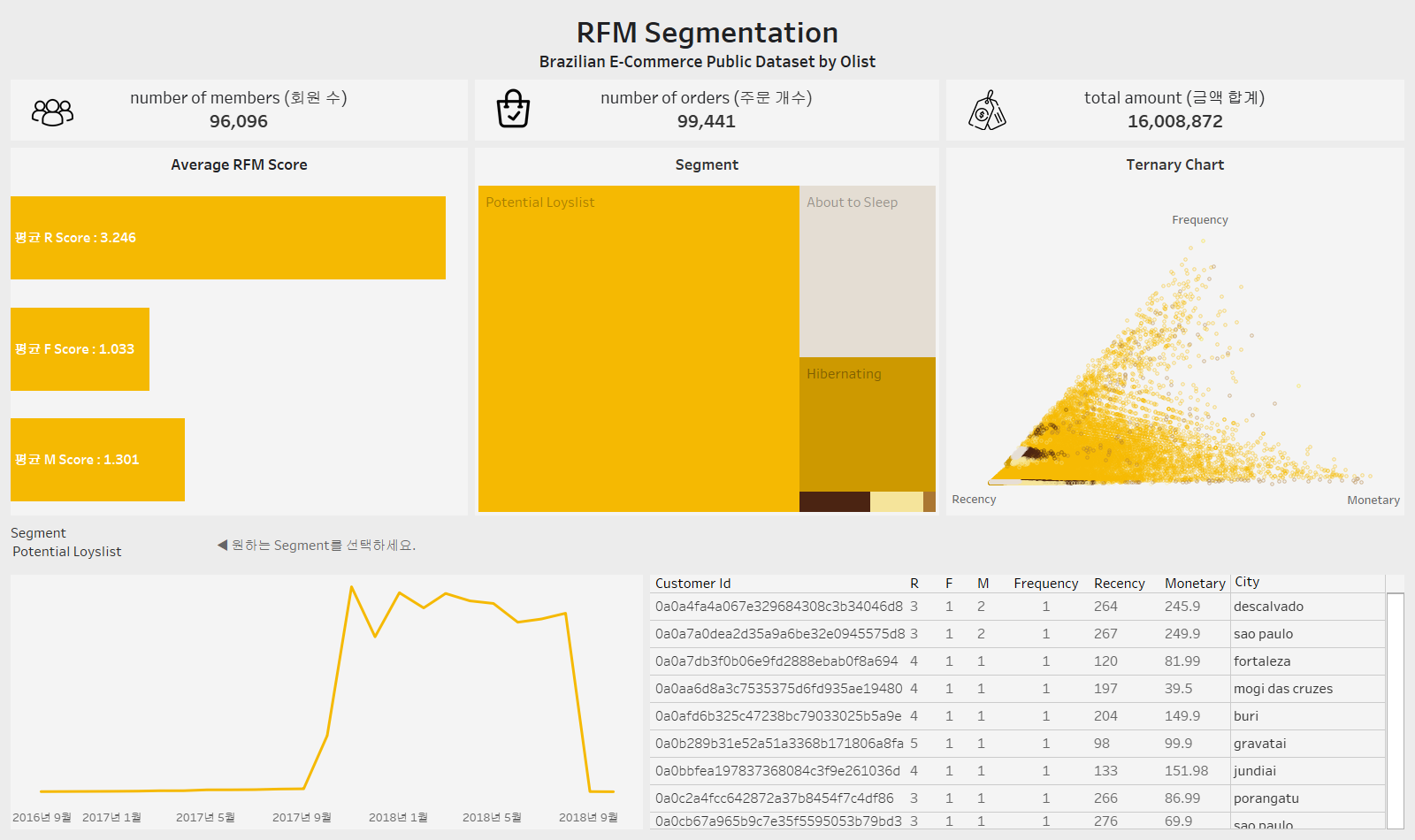
회원 수와 주문 개수가 비슷하기에 1인당 보통 1개의 주문이 있었다는 것을 바로 확인할 수 있고,
고객의 R등급은 평균 3등급, F등급은 평균 1등급, M등급도 평균 1등급입니다.
R등급은 각각 고르게 분포된 편이고, F와 M등급은 대부분의 고객이 1등급에 분포되어 있기에 평균이 이와 같은 결과로 나온 것 같습니다.
Segment의 빈도를 이용해 트리맵을 작성했는데 R이 3~5등급이고 F와 M의 평균이 1~3등급인 고객을 의미하는 'Potential Loyslist' 고객이 매우 많은 것을 볼 수 있습니다.
그리고 상단 오른쪽에는 삼각 도표를 그렸습니다.
각 점을 기준으로 멀어지면 해당 점의 등급은 작아집니다. 예를 들어 Monetary의 점인 오른쪽 꼭짓점을 기준으로 두 점을 비교했을 때, 왼쪽으로 더 많이 간 점이 Monetary의 등급이 오른쪽에 가까운 점보다 1등급에 가깝다는 뜻입니다.
F와 M은 1등급인 고객이 많기 때문에 삼각형의 오른쪽 부분이 비어보입니다.
마지막으로 하단에서 원하는 Segment를 선택하면 해당 Segment 고객들의 구매 횟수를 월별로 보여주고, 고객들의 리스트를 보여줍니다.
여기서 다른 그래프들은 각 열과 행에 어떤 데이터가 들어갔는지 안다면 무난하게 그릴 수 있을 것 같은데,
Ternary chart(삼각 도표)는 여러 가지 계산 필드가 필요해 조금 복잡합니다.
그래서 이와 관련된 코드만 간단하게 알아보겠습니다.


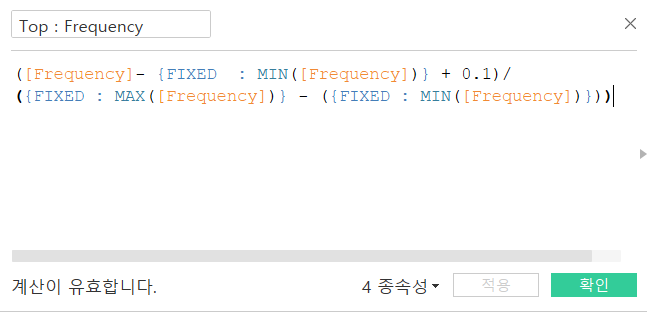
이렇게 각 꼭짓점을 위한 필드를 만들어주었습니다.
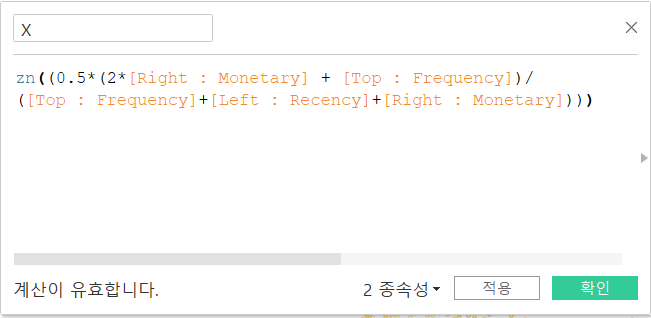

다음으로 X, Y축을 만들어주고
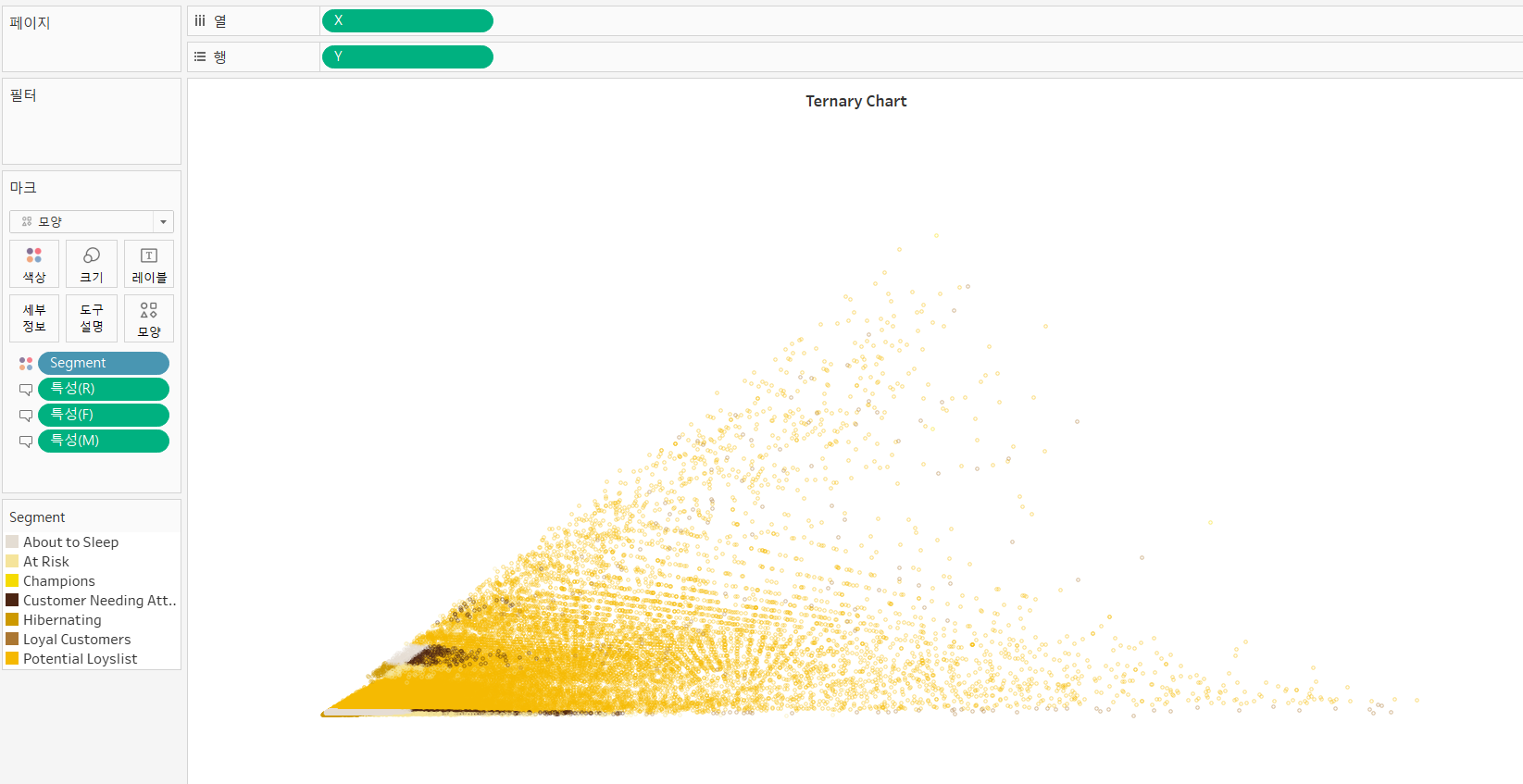
행, 열 , 마크에 위와 같이 넣어주면 완성입니다.
위의 데이터를 이용해 만든 그래프를 보니 Potential Loyslist 그룹이 대부분이어서 노란색이 많이 눈에 띕니다.
https://public.tableau.com/app/profile/.11458342/viz/RFMSegmentationDashboardKaggle/RFMSegmentation
사용한 캐글 데이터가 실제 데이터처럼 부서별로 데이터를 나눠놓은 것 같아 연습해보기 좋은 것 같다는 생각이 들었습니다.
데이터들을 이용해 RFM을 계산하고 Segment로 분류한 후 시각화까지 해보았습니다.
모두 읽어주셔서 감사합니다.😊
'Data Analysis' 카테고리의 다른 글
| 서울시 상권매출 데이터 다중회귀분석/군집분석 프로젝트 (0) | 2022.04.01 |
|---|---|
| 파이썬 단어 간 상관관계 분석해보기 (0) | 2022.02.27 |
| 코멘토 직무부트캠프 후기-데이터분석 실무자와 빅데이터 인프라부터 데이터 분석 경험하기 (0) | 2021.10.26 |